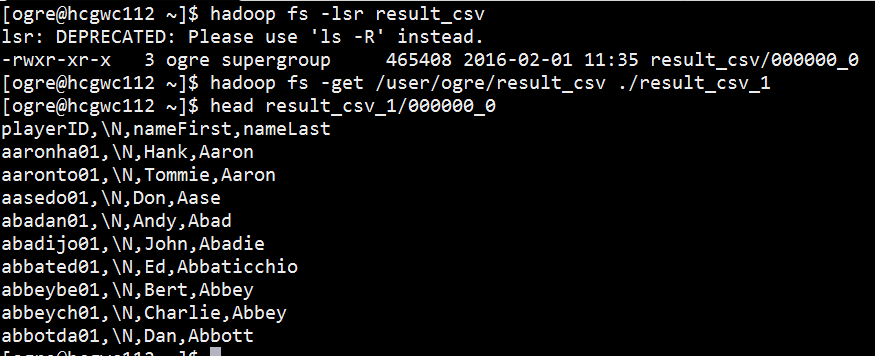
匯出資料表
此方法是透過create result table時指定 LOCATION 在'/user/
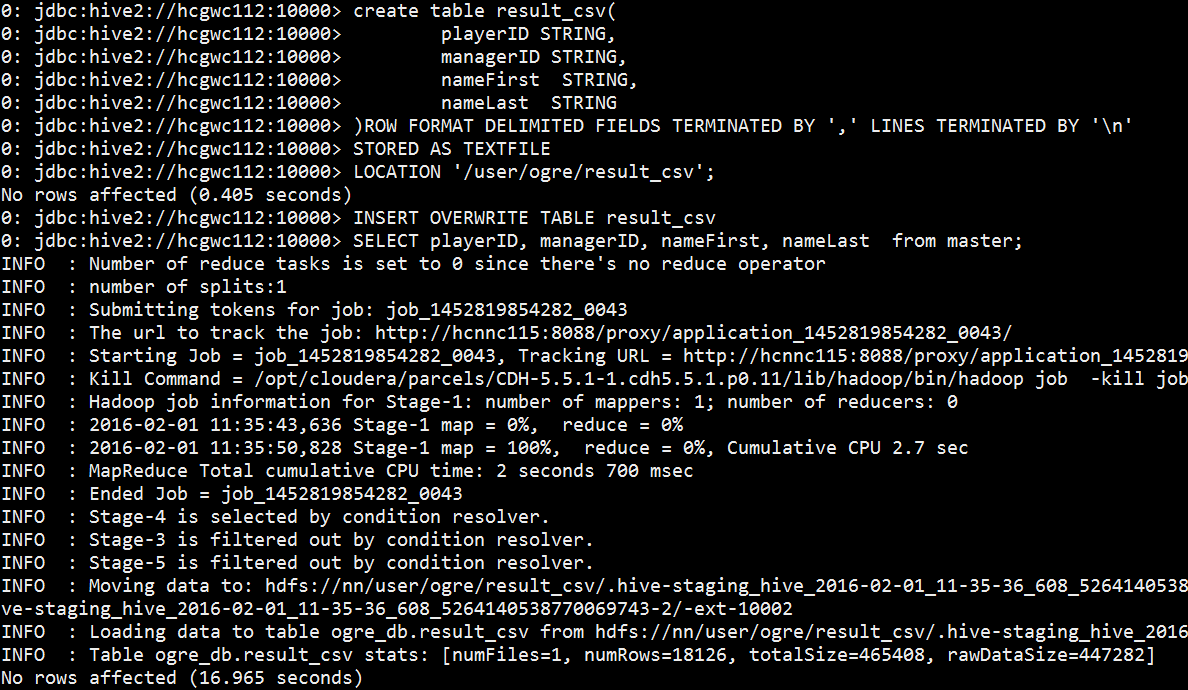
在beeline :
create table result_csv(
playerID STRING,
managerID STRING,
nameFirst STRING,
nameLast STRING
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/<user_name>/result_csv';
INSERT OVERWRITE TABLE result_csv
SELECT playerID, managerID, nameFirst, nameLast from master;
在Linux
$ hadoop fs -get /user/<user_name>/result_csv ./result_csv_1