匯出結果
用 INSERT OVERWRITE DIRECTORY
在beeline :
INSERT OVERWRITE DIRECTORY '/user/<user_name>/hive_result' SELECT * FROM master;
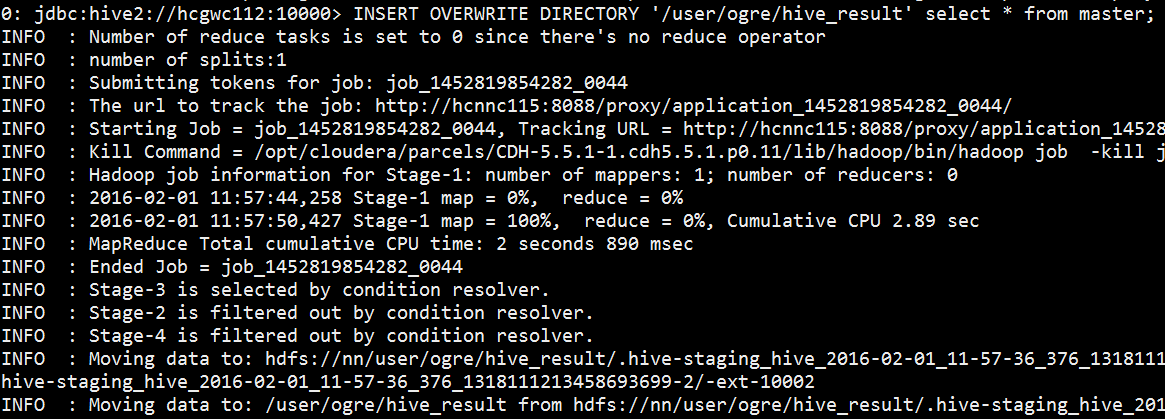
在Linux
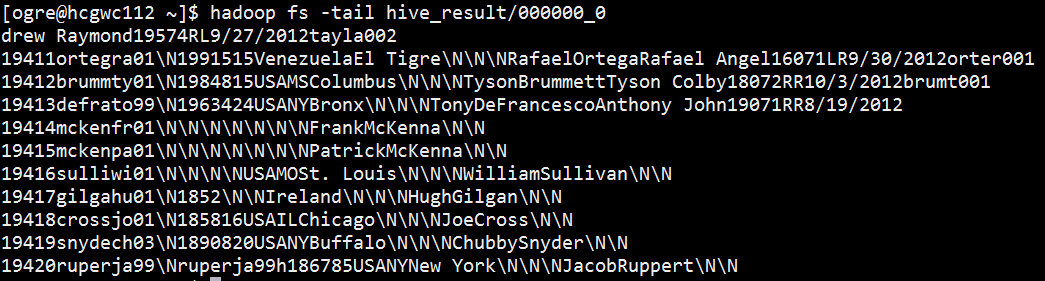
$ hadoop fs -get /user/<user_name>/hive_result ./hive_result1
$ head hive_result1/000000_0
用 INSERT OVERWRITE DIRECTORY
在beeline :
INSERT OVERWRITE DIRECTORY '/user/<user_name>/hive_result' SELECT * FROM master;
在Linux
$ hadoop fs -get /user/<user_name>/hive_result ./hive_result1
$ head hive_result1/000000_0