在R啟用H2O flow
整個程序接近啟動H2O flow Web UI 的Step 3與Step 4。
Step 1: ssh 登入後在terminal執行sparkling-shell,進入sparkling-water shell
$ sparkling-shell
Step 2: 在sparkling-water shell 啟動 sparkling-water cluster
scala> import org.apache.spark.h2o._
scala> val h2oContext = H2OContext.getOrCreate(sc)
在結束上述程序最後,會獲得一組ip和port位置,如下圖所示
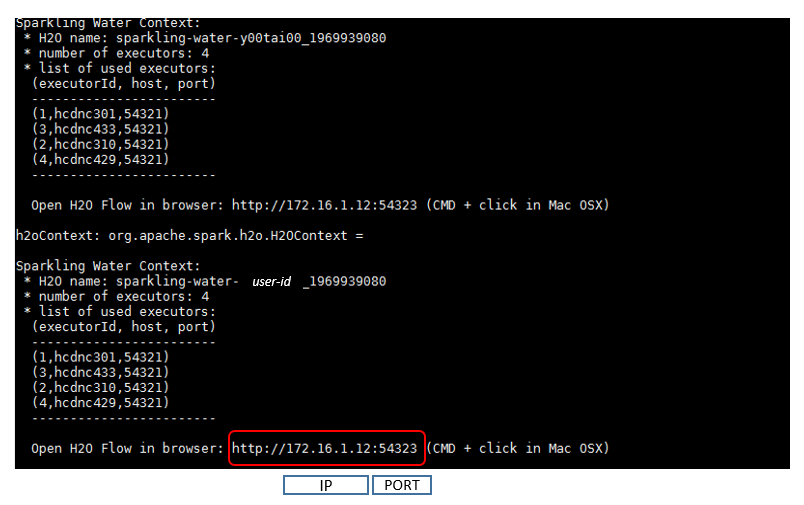
Step 3: 因每個人所分配到的port皆不同,請依提示訊息,此例為:http://172.16.1.12:54323
透過這組指派的IP和port,以上的範例ip="172.16.1.12" port=54323,透過這組ip和port可以直接進入H2O webUI的界面,或是透過R直接進入H2O的cluster。
Step 4: 在R的環境操作H2O cluster方式,不要中斷上面sparkling-shell的環境,同時在新的terminal開啟R。
註: 務必不要中斷sparkling-shell,且務必要開一個terminal。
$ R
Step 5: 在R的環境下安裝H2O套件。
>options(download.file.method = "wget")
>install.packages(c("statmod","RCurl","jsonlite"),
repos="https://cloud.r-project.org")
>install.packages("h2o",type="source",
repos=(c("http://h2o-release.s3.amazonaws.com/h2o/rel-turin/2/R")))
註1: 為配合我們系統上的sparkling環境,不能夠直接使用install.packages("h2o")的方式
註2: 只有第一次使用需要安裝套件,安裝成功後就不再需這執行一步
Step 6: 安裝完成後,就如同其他執行R套件的模式呼叫h2o,為進入我們系統提供的H2O Cluster環境,必須執行以下程序,其中ip和port設定,同樣必須仰賴之前sparkling-shell指派的位置。
> library(h2o)
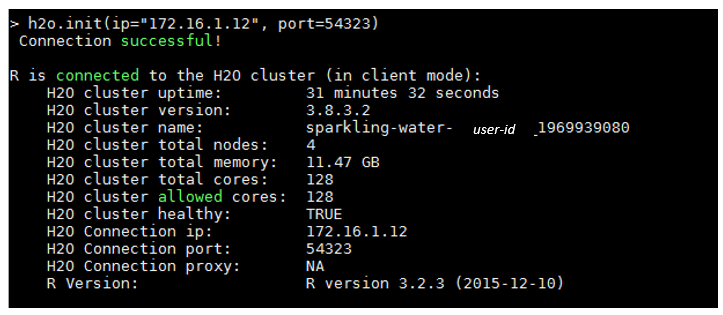
> h2o.init(ip="172.16.1.12", port=54323)
若順利進如設定的H2O Cluster環境,系統上會迴傳以下資訊
接著就可以使用h2o這個套件提供強大的Machine Learning的功能,請參考在R使用H2O應用範例
其他細節請參考H2O官方的說明文件